
Is your content indexed by the world's largest policy database?
We index and provide advanced searching of millions of documents from thousands of organizations. No other service provides more coverage. Policy Commons deepens and speeds research in almost every field.
Basic access is free to registered users.
How we can help you
Uncover your impact in millions of previously hidden sources
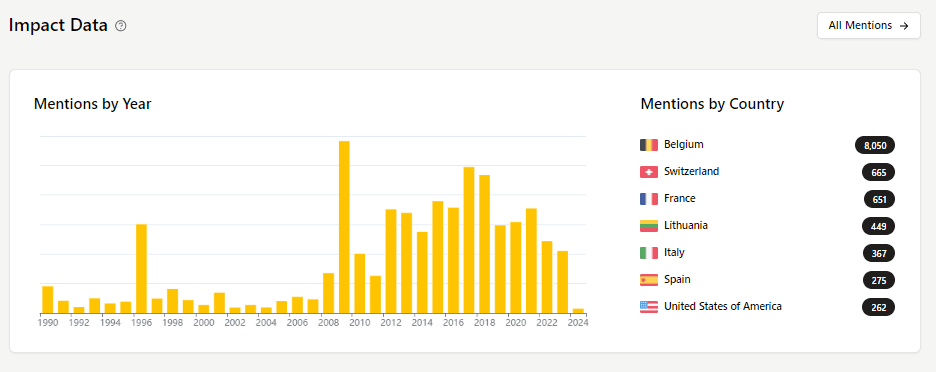
When you measure your impact, how much are you missing because you're not including grey literature? Using our Mentions impact tool, uncover where your organization and its publications are cited or mentioned by thousands frontline policy organizations, including governments. Compare your impact to that of similar organizations. Individual registration for Policy Commons is free for up to fifteen monthly searches—or turn on full access for your institution with a subscription.
Reach an audience of more than 150,000 policymakers
Every day, thousands of scholars, students, and practitioners use our Commons platforms to find materials. Increase the visibility and usage of your reports by ensuring that we index them. We link back to your website, driving traffic to your organization—at no cost to you and with no effort required on your part.
Digitize or publish your archive
We collaborate with all types of organizations to digitize, publish, and preserve older materials. We cover the digitization costs, create a product, and market the content. You receive royalties or a free subscription. Our modern, highly functional platform ensures that your older reports are easily searchable—both for you and your users.

Get in touch
Include your organization in Policy Commons—for free—by connecting with our editor, Toby Green.
Are you missing your real-world impact data found in grey literature?





